
Introduction
This article is a reminder that:
- No matter how good the hardware you purchase is…
- No matter how much you build in redundancy…
- No matter how well you protect against disaster…
There will always be a chance, a scenario, or a point of failure, that can cause you to lose everything on your server. And so to be ready in the event that occurs, you should always make regular backups (and backups of backups, potentially offsite) of any data you consider important, or would be inconvenient to rebuild.
The Setup

So as I’ve posted previously, the homelab setup I run is fairly expensive. I currently have two Dell PowerEdge R630 1U Servers running on VMWare vSphere, as well as a Dell PowerEdge R730XD 2U Server as a NAS running on TrueNAS Core. All of the OS drives are Enterprise grade – either Intel or Dell EMC SSDs. The Dell R630 drives are mirrored in RAID-1 using the internal PERC H730P Mini as the RAID controller.
I had just recently upgraded the RAM in two of the servers to 256GB.
The entire server stack is protected against power surges by an Eaton 5PX1500RTN UPS with an additional battery module.
The Problem
The issue started out as a reported crash on one of the Minecraft servers. I logged in via SSH, and found the server sluggish and unresponsive. I tried running some commands – htop, free, df -h, and nothing worked – the commands just hung. Typically if the OS hard drive fills up, there is some strange activity, but not usually to this extent. I rebooted the server, and it failed to come back up, indicating the OS drive was missing.
I tried logging into the VMware vCenter client but that didn’t work either. I did manage to get into the VMware vSphere ESXi client for the server that these machines were running on. When I checked on the datastores, they were all missing. I rebooted the entire vSphere server and logged into the IDRAC virtual console to see what was going on. I got the following error:
Multibit ECC errors were detected on the RAID controller. If you continue, data corruption can occur. Contact technical support to resolve this issue. Press 'X' to continue or else power off the system, replace the controller and reboot.From this post, it makes sense that if Mutlibit ECC errors are detected, the RAID controller will halt processing, and the drives will not be visible.
I ran a full hardware check, and didn’t get any errors, but I couldn’t run full diagnostics on the RAID controller. The full diagnostics only seemed to check the battery status, although it did run a number of test on the server’s RAM, and everything checked out fine.
If I tried to boot, the machine would halt at the PERC screen and I would have to press ‘X’ to continue, however this could introduce some data corruption. I looked to see if there was another option, but I couldn’t find a way to bypass, so I pressed ‘X’ to continue and booted up the ESXi host.
The Damage
Once I was booted into ESXi, I tried booting up some of the virtual machines that were hosted on it.
The vCenter instance failed to boot completely – so something was definitely corrupted. I followed a few articles and tried moving the files to another datastore, but that just seemed to make the problem worse, and I ended up in this state when attempting to boot:
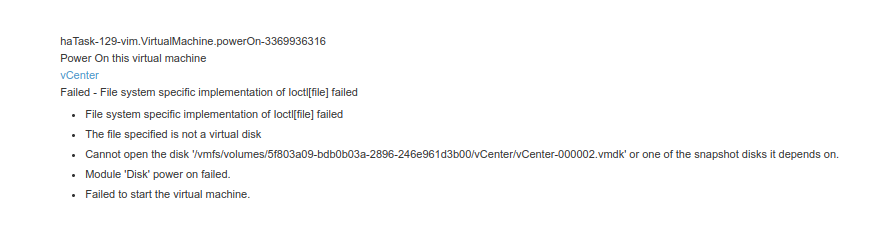
I tried restoring a snapshot, but that failed too, potentially because of the files I had tried moving to another datastore and back.
My FreePBX VOIP instance started up, but the software itself failed to initialize properly. When I went to the web interface, I got an error similar to this:
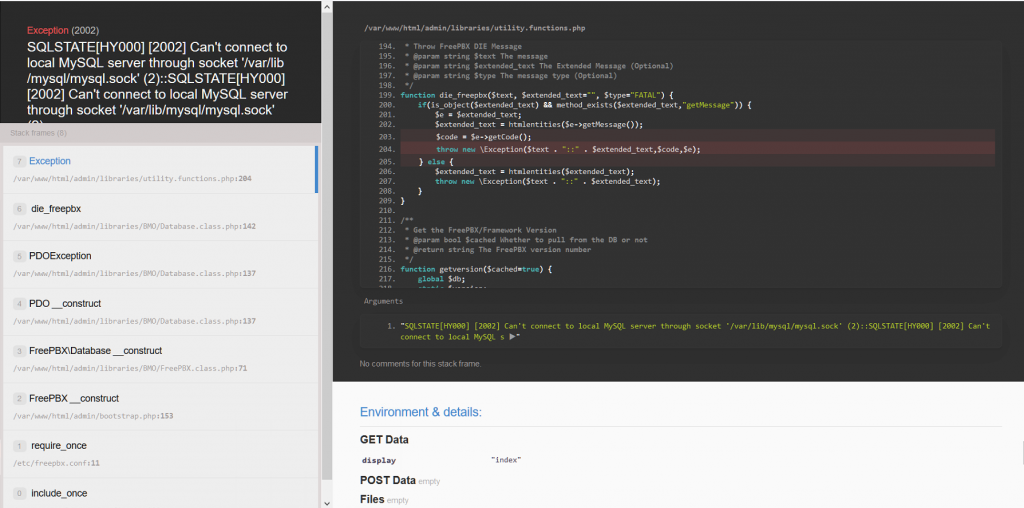
From looking at the logs, the MySQL/MariaDB database was completely corrupted, which was preventing FreePBX from starting up properly.
Fortunately the other machines, such as the Minecraft servers were not affected, and even if they were, I had backups of the critical files on another server and could easily rebuild them. The other VMs were all offline, so nothing had changed (nothing had been written to disk for them).
The Solution
For vCenter, I would have to do a full reinstall. Fortunately, I had recently consolidated all of the VMs onto this one ESXi host, so using vCenter wasn’t critical for daily use.
For the VOIP server, I had an older snapshot of the machine that wasn’t damaged, and I was able to revert to it, then update without issue. I’m lucky that this worked, because the snapshot was stored on the same server and could easily have been corrupted or lost.
Lessons Learned

The first thing I did was order a replacement PERC H730P Mini to replace the one that failed. Although the server appears to be working now, I don’t have a way of running proper diagnostics on it to see if it is a problem with the memory module, or something else. It’s safer just to replace it so it doesn’t have a chance to fail again.
The next step is to rebuild vCenter, as it looks like it’s needed to schedule a task to automate a weekly VM snapshots.
After that, I will look at automating backing up the VM files themselves to the NAS regularly, in case I have a complete drive failure.
And lastly, I will set up automated offsite backup for critical files to cloud storage. I will likely use BackBlaze B2 Cloud Storage as there is native integration with TrueNAS. Tom Lawrence has done at least one video on this topic, so it will likely help with setup.
Conclusion
I’m lucky that nothing critical was lost, but the experience does highlight that even for a homelab, you should make sure to have regular backups so you can restore quickly in the event of a failure. The time and inconvenience of having to set things up again is not worth it.
![]()