
Introduction
On March 19, 2024, ScyllaDB hosted a live training event, going over an Essentials and an Advanced track, covering a number of topics.
I had heard of ScyllaDB through a couple of articles, mainly one blog post about how Discord started off using MongoDB, but as they grew, migrated to Apache Cassandra for additional scalability, fault tolerance, and low maintenance. As they started to see performance issues, they eventually migrated all of their databases, including trillions of messages, over to ScyllaDB. A very interesting article, and it got me curious to learn more about this free, open-source, distributed database system.
Although I have worked with NoSQL databases such as Amazon DynamoDB, and understood some of the basics of storing key-value pairs in a non-relational database, I hadn’t deployed my own distributed database architecture before, so I was very interested in learning more.
What is ScyllaDB?
ScyllaDB is an open-source distributed NoSQL wide-column data store. It was designed to be compatible with Apache Cassandra while achieving significantly higher throughputs and lower latencies. It is written in C++, and uses a sharded design, meaning each CPU core handles a different subset of data. ScyllaDB is compatible with Apache Cassandra protocols, and also implements the Amazon DynamoDB API.
As ScyllaDB is a distributed database system, it uses multiple nodes in a cluster (in a ring-type architecture), which are rack and datacenter aware.
This means that data is automatically replicated across the cluster based on a set Replication Factor (RF), and data is considered successfully written based on a tuneable Consistency Level (CL).
I could go on, but the training documentation on ScyllaDB University is so good, I wouldn’t do it justice, so I would just recommend reviewing the documentation and courses there.
Training Resources
ScyllaDB University is a free platform with a number of courses to learn concepts around ScyllaDB and NoSQL; at both a beginner and advanced level. There are multiple learning paths available:

The training website is very slick, blending in video lessons, technical documents, articles and studies, and hands on lab instructions. You can earn a digital certification after completing a course, and currently (if you’re in the United States), you can receive some Swag as well!

ScyllaDB Essentials Track
As a relative newcomer to ScyllaDB, I attended the Essentials Track, which went over:
- Intro to ScyllaDB – ScyllaDB features and advantages.
- ScyllaDB Core Concepts – An introduction to ScyllaDB and NoSQL, ScyllaDB architecture, data modeling.
- Succeeding with ScyllaDB – Best practices and avoiding common pitfalls.
- Expert Panel with Live Q&A.
Unfortunately, the sessions weren’t recorded, however the slides were made available on the ScyllaDB University website, and I took detailed notes, which I’ve published on my Github page:
- ScyllaDB University Live – Essentials Track – Slides and Resources
- ScyllaDB University Live – Essentials Track – Notes and Links [Github]
ScyllaDB Advanced Track
The Advanced Track for the live event covered:
- Advanced Data Modelling – Materialized Views, Filtering and Denormalization, Secondary Indexes, UDT, Collections, TTL and when to use each.
- What’s New in ScyllaDB – An overview of new features in the latest version of ScyllaDB, including Tablets and consistent topology changes using Raft.
- Building a Real-World Application – How to build a real world application with ScyllaDB, using a hands-on example (with ScyllaDB Cloud) and explaining the data modeling and the design thought process.
As I didn’t attend this track, I wasn’t able to save any notes, but the slides are available here:
Checking out ScyllaDB University

There was an offer as part of the live event, that if you attended the entire event, and completed a course on ScyllaDB University within a certain amount of time, that you would be able to receive some extra swag. I do like swag, and I took an evening to complete this course:
S101: ScyllaDB Essentials – Overview of ScyllaDB and NoSQL Basics
During the course, I was able to spin up a test cluster on ScyllaDB Cloud which used resources in AWS to host the instances. For testing locally, there were also Docker images available, and I was able to set up a mini cluster with multiple “datacenters” to test with. To do this, I needed to have all of the prerequisites installed locally including docker-cli, docker-compose, and Docker Desktop. The Docker Docs have instructions to install the components on multiple platforms.
To show how easy this was, these are the commands I ran, while giving enough time (about 60 seconds) between docker-compose commands for the nodes to come up:
git clone https://github.com/scylladb/scylla-code-samples.git
cd scylla-code-samples/mms
docker-compose up -d
docker-compose -f docker-compose-dc2.yml up -d
docker exec -it scylla-node1 nodetool statusThe docker-compose commands launched multiple ScyllaDB nodes as separate Docker containers, with configuration on how to communicate with each other:

The ScyllaDB nodetool status command can be used to show the state of all nodes in the cluster. It can be executed from within the Docker container against any of the nodes:
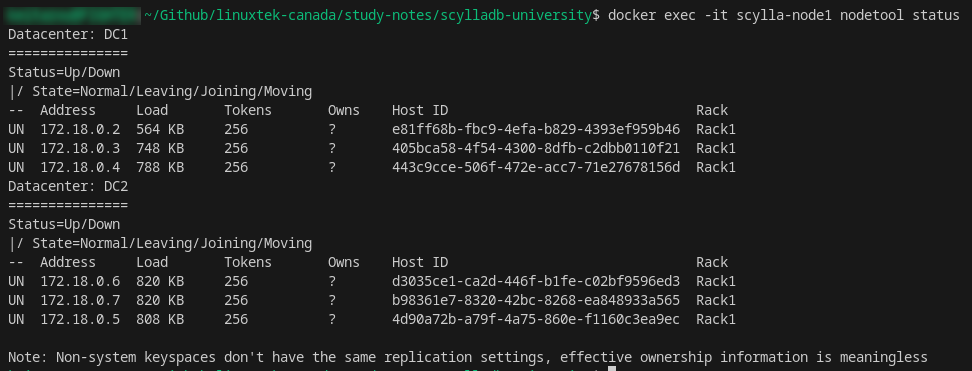
In this screenshot, you can see that the nodes are divided into two Datacenters, with 3 nodes in each “Rack”. As part of the labs, we took down some of the nodes, or an entire datacenter, and then attempted to write data after setting a Consistency Level (CL) that wouldn’t allow a write to be successful. The write failed, and we adjusted the CL to a more local value (LOCAL_QUORUM), and was then able to read/write data properly.
More To Learn
After finishing the Essentials course, I really want to check out more about configuring ScyllaDB in an Enterprise environment.
During the “Succeeding with ScyllaDB” presentation, there were a lot of important points to keep in mind such as:
- Using packaged AMIs, or building your own image.
- If using your own image, be sure to tune the CPUs for use between ScyllaDB and the NICs, as changing later is painful.
- Designing for High Availability using Snitches, Racks, and Replication settings.
- Ensuring you do not use SimpleSnitch when deploying in production.
- For example, using EC2Snitch or EC2MultiRegionSnitch on AWS, allowing the nodes to read configuration data from Amazon’s EC2 registry services.
- Understanding using GossipingPropertyFileSnitch (ideal for production) when working with multi-cluster deployments with nodes in various datacenters.
- How to run maintenance, upgrades, and repairs on ScyllaDB.
- Common pitfalls when working with ScyllaDB, including shutting down nodes properly, clock synchronization, retry storms, and garbage collection.
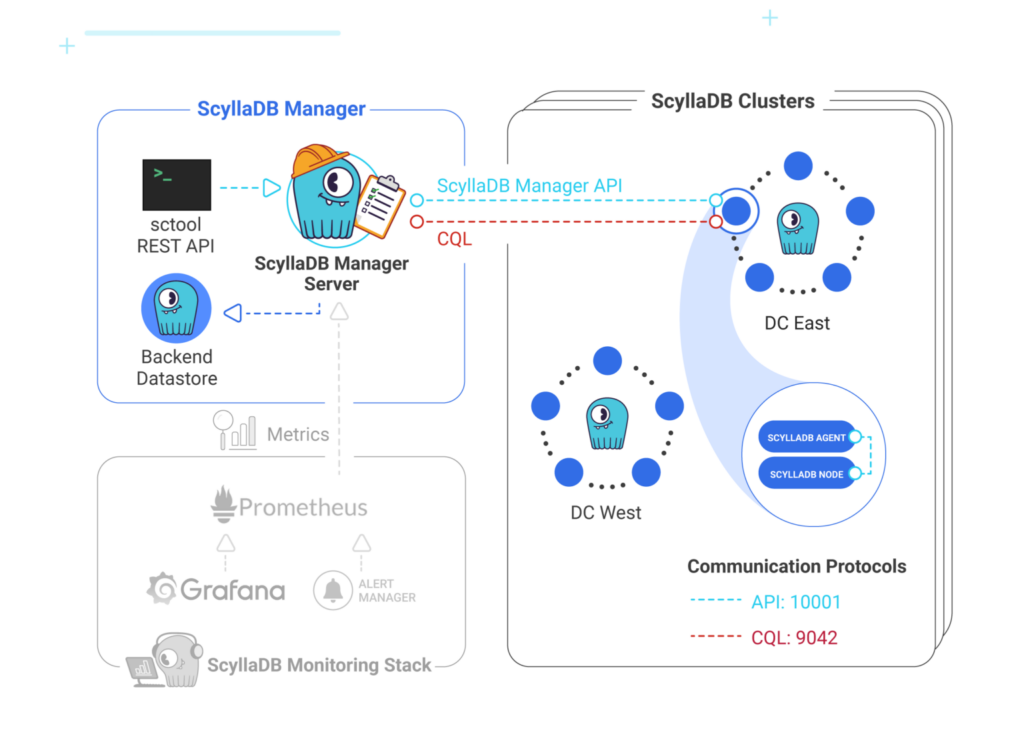
ScyllaDB Manager is an automated cluster management application for ScyllaDB, which can automate repetitive tasks, manage backup and restore, handle repairs, and integrates with the ScyllaDB Monitoring Stack for observability.
ScyllaDB on Kubernetes – The ScyllaDB Operator

I’m also very interested to try out ScyllaDB on Kubernetes, using the ScyllaDB Operator. The ScyllaDB Operator automates the cluster deployment process and tasks related to operating a ScyllaDB cluster, such as scaling, backup, auto-healing, rolling configuration changes, upgrades, and more.
The ScyllaDB Operator is fully compatible with bare metal Kubernetes clusters, Google Kubernetes Engine (GKE), and Amazon Elastic Kubernetes Service (EKS).
This is a great video that introduces some of the Kubernetes concepts, the pain points of running ScyllaDB natively on Kubernetes, and how the Kubernetes Operator extends functionality to properly manage the ScyllaDB nodes on Kubernetes:
Conclusion

Overall, I’m very impressed with the ScyllaDB University Live event, the free training courses and resources, and the options available to utilize this technology. I’m sure I’ll be doing some more courses, and considering using ScyllaDB for some applications in the future. I highly recommend checking out their learning platform.

Resources
- ScyllaDB Main Site
- ScyllaDB University – Training Courses and Documentation
- ScyllaDB University Live – Essentials Track – Slides and Resources
- ScyllaDB University Live – Advanced Track – Slides and Resources
- ScyllaDB University Live – LinuxTek Github Notes
- ScyallaDB – Github Code Samples
![]()